动态的内容往往性能都非常差,所以一般的nginx+fastcgi的模式下性能肯定都是卡在后面cgi上。尤其是小内存的VPS上的一些配置使得mysql的速度也非常慢,所以这样的情况就很明显了。
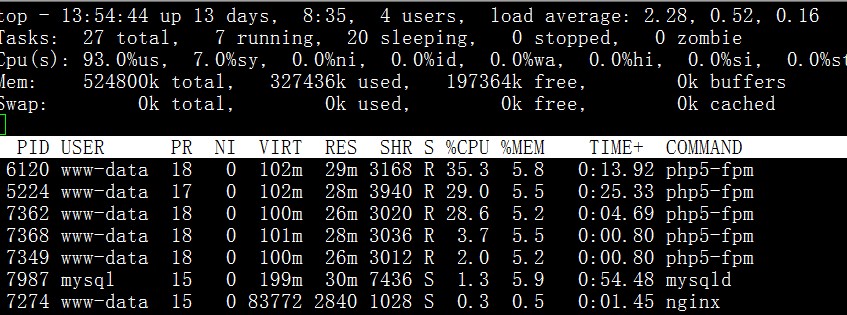
上图就是随便压测一下,QPS非常低,但是php-fpm就把CPU都耗完了。
所可以考虑直接在fastcgi里做一下cache,这样如果某篇文章的访问量比较大的时候(目前我的blog还没有这样的访问量)可以直接使用cache的文件,这样的话性能就不是问题了,一般的流量nginx在小vps上都是可以轻松应对的。配置如下
[text]
map $upstream_addr $hitstatus {
default ‘cache’ ;
~unix ‘nocache’;
}
map $http_user_agent $agent {
default ‘normal’;
~monitor ‘dnspod’;
}
fastcgi_cache_path /var/cache/nginx levels=1:2 keys_zone=blog:10m inactive=2m max_size=50m;
server {
listen [::]:443 ssl so_keepalive=on;
listen [::]:80 so_keepalive=on;
root /home/www/blog;
index index.html index.htm index.php;
server_name localhost;
ssl_certificate cert/server.crt;
ssl_certificate_key cert/server.key;
ssl_session_timeout 5m;
ssl_session_cache shared:sslcache:1m;
ssl_protocols SSLv3 TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
try_files $uri $uri/ /index.html;
# Uncomment to enable naxsi on this location
# include /etc/nginx/naxsi.rules
if ($http_user_agent ~ monitor ) {
return 200;
access_log off;
}
if ($http_user_agent ~ monitor ) {
return 200;
access_log off;
}
fastcgi_cache blog;
fastcgi_cache_valid 200 302 10m;
fastcgi_cache_valid 404 1m;
fastcgi_cache_min_uses 2;
fastcgi_cache_methods GET HEAD;
fastcgi_cache_key "$scheme$host$agent$request_uri$server_protocol$request_method";
add_header hit $hitstatus;
expires modified +1h;
}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
location ~ (wp\-.*\.php|xmlrpc.php){
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php5-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_intercept_errors on;
fastcgi_buffers 1024 4k;
fastcgi_buffer_size 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_send_timeout 60;
fastcgi_read_timeout 60;
fastcgi_connect_timeout 60;
add_header hit $hitstatus;
}
location ~ \.php$ {
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass unix:/var/run/php5-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_intercept_errors on;
fastcgi_buffers 1024 4k;
fastcgi_buffer_size 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_send_timeout 60;
fastcgi_read_timeout 60;
fastcgi_connect_timeout 60;
# add cache setting
fastcgi_cache blog;
fastcgi_cache_valid 200 302 10m;
fastcgi_cache_valid 404 1m;
fastcgi_cache_min_uses 2;
fastcgi_cache_methods GET HEAD;
fastcgi_cache_key "$scheme$host$agent$request_uri$server_protocol$request_method";
add_header hit $hitstatus;
expires modified +1h;
}
[/text]
cache_key的设置为整个“协议-请求方法-host-url(含义参数)”。对于后台的管理页面单独进行配置,不进行缓存,其他的普通页面进行缓存。配置好后可以访问一个url几次,看到缓存的文件生成,不过我的OpenVZ的VPS上应该是挂载文件系统的时候就被加了noatime,所以看不到访问时间的变化。用ab实际测试了一下,性能比之前好多了,基本上不会有看到php-fpm占有CPU的时候。
缓存的时间并没有设置得非常长,主要是对于2分钟进行一篇blog的查询应该是没有任何问题的。
当然,设置了缓存后也有负面的作用,就是修改了的文章需要等有2分钟没有访问才能看到最新版。
update log:根据后面的遇到的一些问题做了调整,包括根据user-agent的单独处理、之前忘记加request_method引发的问题 ,2013-4-5。