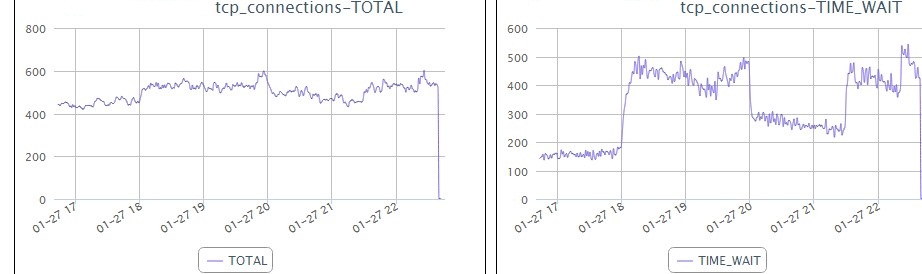
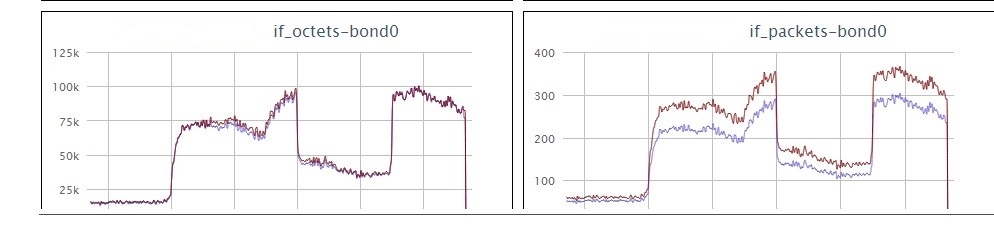
今天遇到了一个和dns ttl相关的问题。线上一个nginx服务器代理了一些外部的资源,把外部的http的资源变成https的供我们自己的https页面上用。
但是今天看到了有很多错误日志,显示的是连upstream的机器失败了。我看了一下配置文件,直接在nginx服务器上访问配置的url是正常访问的。再在nginx服务器上解析了一下对应的IP,发现和错误日志里显示的不一样了。看样子是外部的dns切换了IP,nginx一直是在访问老的失效的IP。
网上看了一下nginx的WIKI,也问了一下tengine的开发同学。nginx wiki上说是会遵循DNS的ttl设置,但是结果确实不是这样。自己简单测试了一下。
测试环境:
1. 1台linux服务器,装上nginx-1.2.8即可。
2. 1台linux服务器跑dnsmasq,设置好ttl并开启日志,也在上面装了wireshark方便抓包。
配置文件如下
[text]
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8888;
server_name localhost;
charset utf-8;
location / {
root /home/admin/soft;
index index.html index.htm;
autoindex on;
}
}
server {
listen 9001;
server_name localhost;
charset utf-8;
location / {
proxy_pass http://dnstest;
}
}
upstream dnstest {
server nginx.test.org:8888;
}
}
[/text]
发现启动的时候会做4次dns查询,但是后面无论多久是不会重新进行nginx.test.org的查询的,而wireshark显示TTL确实是被置为了10s。
[text]
Domain Name System (response)
[Request In: 7]
[Time: 0.000074000 seconds]
Transaction ID: 0x925f
Flags: 0x8580 (Standard query response, No error)
1… …. …. …. = Response: Message is a response
.000 0… …. …. = Opcode: Standard query (0)
…. .1.. …. …. = Authoritative: Server is an authority for domain
…. ..0. …. …. = Truncated: Message is not truncated
…. …1 …. …. = Recursion desired: Do query recursively
…. …. 1… …. = Recursion available: Server can do recursive queries
…. …. .0.. …. = Z: reserved (0)
…. …. ..0. …. = Answer authenticated: Answer/authority portion was not authenticated by the server
…. …. …. 0000 = Reply code: No error (0)
Questions: 1
Answer RRs: 1
Authority RRs: 0
Additional RRs: 0
Queries
nginx.test.org: type A, class IN
Name: nginx.test.org
Type: A (Host address)
Class: IN (0x0001)
Answers
nginx.test.org: type A, class IN, addr 220.xx.xx.xx
Name: nginx.test.org
Type: A (Host address)
Class: IN (0x0001)
Time to live: 10 seconds
Data length: 4
Addr: 220.xx.xx.xx
[/text]
另外设置了resolver 220.xxx.xxx.xx valid=10s;发现还是不会在指定的时间内更新。咨询文景,得知只能采用proxy_pass http://$host这种做正向代理才能每次动态查询dns。
自己测试了一下其实只有另外加上resolver才能使得nginx遵循ttl时间的设置。
[text]
resolver 220.xx.xx.xx valid=15s;
….
server {
listen 9002;
server_name localhost;
charset utf-8;
location / {
proxy_pass http://$http_host:8888;
}
}
[/text]
[text]
Apr 8 14:22:45 dnsmasq[6970]: query[A] nginx.test.org from 220.xx.xx.xx
Apr 8 14:22:45 dnsmasq[6970]: /home/admin/dnsmasq/dnsmasq.hosts nginx.test.org is 220.xx.xx.xx
Apr 8 14:23:01 dnsmasq[6970]: query[A] nginx.test.org from 220.xx.xx.xx
Apr 8 14:23:01 dnsmasq[6970]: /home/admin/dnsmasq/dnsmasq.hosts nginx.test.org is 220.xx.xx.xx
Apr 8 14:23:17 dnsmasq[6970]: query[A] nginx.test.org from 220.xx.xx.xx
Apr 8 14:23:17 dnsmasq[6970]: /home/admin/dnsmasq/dnsmasq.hosts nginx.test.org is 220.xx.xx.xx
Apr 8 14:23:33 dnsmasq[6970]: query[A] nginx.test.org from 220.xx.xx.xx
Apr 8 14:23:33 dnsmasq[6970]: /home/admin/dnsmasq/dnsmasq.hosts nginx.test.org is 220.xx.xx.xx
[/text]
最终才能得到前面的这种效果,每个15s重新查询一次。