做公有云的应该都能感受到比做私有云多N倍的痛苦。比如服务器硬件的问题,如果是内部的应用按理说应用都做到了无状态,随便挂几个机器基本没有任何影响,把机器下线慢慢修就行。但是对于有上十万台服务器规模的人来说,每周挂几十个机器是非常非常平常的,有时内核有bug你也无能为力,升级肯定是需要重启机器的,会对上面跑的VM造成影响,不升级就只有等死。虽然说xen和kvm都是有热迁移,但是实际效果往往差强人意,比如当每秒钟内存内读写的内容比网络速度快的时候,就永远不可能完成热迁移了,如果谁的VM上跑了个memcache之类的,基本就没法迁移。另外很多负载比较重的VM,迁移起来可能对服务的影响也比较大。
在自己的两台笔记本上测试了一下KVM的迁移,整理一下。
- 每台笔记本上都是跑的debian testing,先是修改/etc/network/interfaces配置一下网桥(VM都是使用桥接的形式,每个VM和笔记本获取到的IP都是1个网段)
pm@debian:~ $ cat /etc/network/interfaces
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
#allow-hotplug eth0
#NetworkManager
#iface eth0 inet dhcp
auto br0
iface br0 inet dhcp
bridge_ports eth0
bridge_fd 0
bridge_maxwait 0
- 安装基本的包
aptitude install qemu-kvm libvirt-bin virt-manager virt-top
- 创建镜像文件,从ISO安装系统
3.1 create image file
qemu-img create -f qcow2 debian3.qcow2 10G
如果要调整大小,比如增大size,可以直接命令操作
qemu-img resize debian3.qcow2 +2G
3.2安装系统,sudo 运行一下脚本就可以安装了。
$ cat install_debian3.sh
virt-install \
--name=debian3 \
--os-type=linux \
--os-variant=debianwheezy \
--vcpus=2 \
--ram=1024 \
--accelerate \
--hvm \
--vnc \
--vncport=6668 \
--network=bridge=br0,mac=RANDOM,model=virtio \
--disk path=/home/pm/image/debian3.qcow2,format=qcow2,bus=virtio,cache=writeback \
--cdrom=/home/pm/downloads/debian-7.2.0-amd64-xfce-CD-1.iso
- virsh下启动系统,使用vnc登录进去(知道IP也可以直接ssh登录)
sudo virsh list --all
sudo virsh start debian3
sudo virsh shutdown debian3
sudo virsh edit debian3 (edit domain xml config file)
sudo virsh dumpxml debian3
配置文件的修改直接使用virsh edit操作,不要直接去改/etc/libvirt/qemu/下的内容。
sudo cat /etc/libvirt/qemu/debian3.xml
sudo virsh define /etc/libvirt/qemu/debian3.xml
- 本地clone一个VM,比如从debian3 克隆一个debian0出来。
sudo virt-clone --connect=qemu:///system -o debian3 -n debian0 -f /home/pm/image/debian0.qcow2
- 使用migrate在线迁移(需要先打通到目标机器的SSH信任登录)
6.1无共享存储的迁移(迁移的时候会实时传输镜像内的数据)
在迁移的源机器上:
sudo virsh migrate --copy-storage-all --tunnelled --p2p --verbose --live debian3 qemu+ssh://10.1.1.194/system
目标服务器的后续操作:
sudo virsh dumpxml debian3 >/etc/libvirt/qemu/debian3.xml
sudo virsh define /etc/libvirt/qemu/debian3.xml
6.2 使用NSF做共享存储的迁移
先在源机器上设置一下nfs共享,然后在目标机器上把这个目录挂载上去,需要非常注意NFS的权限,两个机器上相同 用户的用户id是否一致等等,反正有问题就看日志解决。迁移的时候比较简单:
virsh # migrate --p2p --tunnelled --verbose --timeout 3600 --live debian220 qemu+ssh://10.1.1.194/system
Migration: [100 %]
迁移完成后也是需要
sudo virsh dumpxml debian220 > debian220.xml && sudo virsh define debian220
- VM网络带宽的限制,比如限制带宽为4M可以在interface段内定义一下bandwidth。
<interface type='bridge'>
<mac address='52:54:00:cf:0f:f1'/>
<source bridge='br0'/>
<model type='virtio'/>
<bandwidth>
<inbound average='512' peak='550' burst='520'/>
<outbound average='512' peak='550' burst='520'/>
</bandwidth>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</interface>
- cpu资源的设置一方面可以设置VCPU的数量,另外也可以通过显示的cpu绑定,比如设置了2个VCPU但是实际都是被绑定到了1个核上
<vcpu placement='static' cpuset='1'>2</vcpu>
<cputune>
<shares>2048</shares>
<vcpupin vcpu='0' cpuset='1'/>
<vcpupin vcpu='1' cpuset='1'/>
</cputune>
- IO的资源限制
可以使用blkdeviotune来做操作
virsh blkdeviotune debian220 vda --read-bytes-sec 20000000 --write-bytes-sec 1000000 --total-iops-sec 80 --read-iops-sec 0 --write-iops-sec 0 --live (or --config)
virsh # help blkdeviotune
NAME
blkdeviotune - Set or query a block device I/O tuning parameters.
SYNOPSIS
blkdeviotune <domain> <device> [--total-bytes-sec <number>] [--read-bytes-sec <number>] [--write-bytes-sec <number>] [--total-iops-sec <number>] [--read-iops-sec <number>] [--write-iops-sec <number>] [--config] [--live] [--current]
DESCRIPTION
Set or query disk I/O parameters such as block throttling.
OPTIONS
[--domain] <string> domain name, id or uuid
[--device] <string> block device
--total-bytes-sec <number> total throughput limit in bytes per second
--read-bytes-sec <number> read throughput limit in bytes per second
--write-bytes-sec <number> write throughput limit in bytes per second
--total-iops-sec <number> total I/O operations limit per second
--read-iops-sec <number> read I/O operations limit per second
--write-iops-sec <number> write I/O operations limit per second
--config affect next boot
--live affect running domain
--current affect current domain
也可以直接edit手改xml文件。
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2' cache='writeback'/>
<source file='/home/pm/image/debian220.qcow2'/>
<target dev='vda' bus='virtio'/>
<iotune>
<read_bytes_sec>20000000</read_bytes_sec>
<write_bytes_sec>10000000</write_bytes_sec>
<total_iops_sec>0</total_iops_sec>
</iotune>
<address type='pci' domain='0x0000' bus='0x00' slot='0x04' function='0x0'/>
</disk>
当iops不是瓶颈的时候(dd测试的时候可以把bs设置的大点,为了测试方便先不限制iops),限制读的速度是20M/S,写入的速度10M/S。
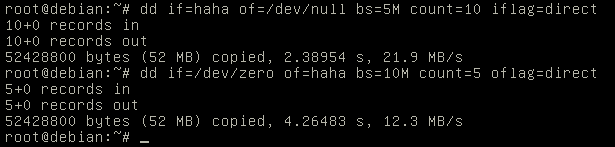
- 配置console
串口的配置主要是guest os内需要改很多配置
echo “ttyS0″ >> /etc/securetty
在/etc/grub.conf文件中为内核添加参数: console=ttyS0
在/etc/inittab中添加agetty:
S0:12345:respawn:/sbin/agetty ttyS0 115200
- 热插拔USB设备
以我的一个罗技的无线鼠标接收器测试
pm@debian:~ $ lsusb |grep Logitech
Bus 001 Device 006: ID 046d:c52b Logitech, Inc. Unifying Receiver
新建一个xml文件
pm@debian:~ $ cat usb.xml
&lt;hostdev mode='subsystem' type='usb'&gt;
&lt;source&gt;
&lt;vendor id='0x046d'/&gt;
&lt;product id='0xc52b'/&gt;
&lt;/source&gt;
&lt;/hostdev&gt;
virsh # attach-device debian220 usb.xml
Device attached successfully
#动态卸载命令
virsh # detach-device debian220 usb.xml
Device detached successfully
# 保存到配置文件内
virsh # attach-device debian220 usb.xml --config
Device attached successfully
#如果当前USB设备已经attach到MV内,并且配置文件也有改设备,可以把设备从配置文件剔除。
virsh # detach-device debian220 usb.xml --config
Device detached successfully
--config保持到配置后可以dumpxml 看到新增了相应的配置段。
&lt;hostdev mode='subsystem' type='usb' managed='no'&gt;
&lt;source&gt;
&lt;vendor id='0x046d'/&gt;
&lt;product id='0xc52b'/&gt;
&lt;/source&gt;
&lt;/hostdev&gt;
在VM内对比加载和卸载前后
root@debian:~# lsusb
Bus 001 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 002: ID 0627:0001 Adomax Technology Co., Ltd
Bus 001 Device 003: ID 0409:55aa NEC Corp. Hub
Bus 001 Device 004: ID 046d:c52b Logitech, Inc. Unifying Receiver
root@debian:~# lsusb
Bus 001 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
Bus 001 Device 002: ID 0627:0001 Adomax Technology Co., Ltd
Bus 001 Device 003: ID 0409:55aa NEC Corp. Hub
其他需要注意的事项:
1. 如果只是自己的机器上跑VM玩玩,IO方面可以使用virtio,并且配置cache的模式为writeback,不过配置成writeback后不能进行在线迁移了,因为这样可能出现一部分数据还在内存中没有写到磁盘,所以不允许这个cache模式下的迁移。我自己实际测试的时候是virsh edit把cache模式改为none了。否则会有报错:
virsh # migrate --p2p --tunnelled --verbose --timeout 3600 --live debian220 qemu+ssh://10.1.1.194/system
error: Unsafe migration: Migration may lead to data corruption if disks use cache != none
cache=writeback,bus=virtio
2. 网卡也设置使用virtio,性能会好很多。
mode=virtio
3. 如果要给VM添加其他的设备,比如USB设备之类的可以使用attach-device直接把定义到一个xml文件的设备添加进去。
4. qcow2格式的镜像文件在迁移的时候不只是迁移了使用的块。。自己创建的10G的镜像就直接传输了10G的数据,这个在实际线上估计接受不了,传输量太大,签约的时候目标机器的IO压力会非常大。
参考文档:
1. http://libvirt.org/docs.html
2. http://www.linux-kvm.org/page/HOWTO
