
http段增加配置
server {
listen 80;
server_name status.taobao.com;
location = /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
}
http段增加配置
server {
listen 80;
server_name status.taobao.com;
location = /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
deny all;
}
}
直接把这个服务关闭了,测试了不影响带外登陆。
getty@tty1.service:
service.dead:
- enable: False
- provider: systemd
对比一下docker overlay、calico和host网络的带宽,延迟。
netperf1:
image: netperf:1.0
net: vnet
restart: always
mem_limit: 20480M
labels:
- "com.alipay.proj=netperf"
environment:
- "affinity:container!=*netperf*"
- "constraint:node==*test1*"
command: /sbin/init
netperf2:
image: netperf:1.0
net: vnet
restart: always
mem_limit: 20480M
labels:
- "com.alipay.proj=netperf"
environment:
- "affinity:container!=*netperf*"
- "constraint:node==*test2*"
command: /sbin/init
netperf1:
image: netperf:1.0
net: vxlan
restart: always
mem_limit: 20480M
labels:
- "com.alipay.proj=netperf"
environment:
- "affinity:container!=*netperf*"
- "constraint:node==*test1*"
command: /sbin/init
netperf2:
image: netperf:1.0
net: vxlan
restart: always
mem_limit: 20480M
labels:
- "com.alipay.proj=netperf"
environment:
- "affinity:container!=*netperf*"
- "constraint:node==*test2*"
command: /sbin/init
netperf1:
image: netperf:1.0
net: host
restart: always
mem_limit: 20480M
labels:
- "com.alipay.proj=netperf"
environment:
- "affinity:container!=*netperf*"
- "constraint:node==*test1*"
command: /sbin/init
netperf2:
image: netperf:1.0
net: host
restart: always
mem_limit: 20480M
labels:
- "com.alipay.proj=netperf"
environment:
- "affinity:container!=*netperf*"
- "constraint:node==*test2*"
command: /sbin/init
[root@satest1 /]# time qperf netperf_netperf2_1 --time 20 tcp_bw tcp_lat udp_lat
tcp_bw:
bw = 118 MB/sec
tcp_lat:
latency = 48.2 us
udp_lat:
latency = 46.1 us
[root@55fd7810562d /]# time qperf netperf_netperf2_1 --time 20 tcp_bw tcp_lat udp_lat
tcp_bw:
bw = 118 MB/sec
tcp_lat:
latency = 54.1 us
udp_lat:
latency = 50.3 us
[root@1472d4ce9a24 /]# time qperf netperf_netperf2_1 --time 20 tcp_bw tcp_lat udp_lat
tcp_bw:
bw = 114 MB/sec
tcp_lat:
latency = 63.5 us
udp_lat:
latency = 58.5 us
如果使用docker默认的ipam创建calico网络,则不支持访问策略控制。
1. 创建pool
2. 创建network
3. 更新profile增加2个互相访问
之前为了测试,直接使用pipework把宿主机器上的一张网卡塞到容器内,整个过程如下
/usr/sbin/pipework --direct-phys enp6s0f3 106aac56d226 192.170.100.202/24
docker inspect '--format={{ .State.Pid }}' 106aac56d226
DOCKERPID=44810
NSPID=44810
ln -s /proc/44810/ns/net /var/run/netns/44810
ip link show enp6s0f3
ip link set enp6s0f3 up
ip link set enp6s0f3 netns 44810
ip netns exec 44810 ip link set enp6s0f3 name eth1
ipcalc -b 192.170.100.202/24
ip netns exec 44810 ip addr add 192.170.100.202/24 brd 192.170.100.255 dev eth1
ip netns exec 44810 ip link set eth1 up
ip netns exec 44810 arping -c 1 -A -I eth1 192.170.100.202
当前虽然docker网络的解决方案很多,但是docker官方的方案都不是太成熟,原因有以下几点:
1. host/bridge这种模式只适合自己在virtualbox上玩玩,bridge模式NAT依赖contrack表在session多的时候会让你机器都登陆不上(不要YY把nf_conntrack_max配置的大点能高枕无忧)。
2. 剩下的macvlan/ipvlan其实是更适合中大型企业现有VLAN模型的方案,无耐对内核的要求太高,基本就是没法用。没人会因为尝试docker把生产OS切到4.X的版本。
3. 在最新版本的docker中,已经可以创建overlay的网络类型了。但是稳定性还有待考验。
在我看来,一个成熟的虚拟化网络整体方案,需要满足2个场景:
1. 支持传统的基本VLAN模式,这是能在企业内快速实施的基础条件。因此现在大家的企业对docker的扩展都是在用ovs之类的支持vlan。
2. 支持overlay,但是这个overlay不是纯孤立的一个网络。需要能做到跨network的联通,也要能做到与真实网络的打通。
目前尝试过calico和官方的overlay方案。
calico本质上是自己在一组机器上创建一个BGP网络,自己控制一个虚拟网络中下一跳得路由,三层能通的机器都部署calico。如果是在共有云的机器上,因为大家都会在宿主机器上做arp绑定等控制,只需要加一下IPIP让豹纹发出之前做一次ipip封装即可。对calico的测试用得比较多,一个主管的判断就是:能用,不够可靠。所谓的不够可靠主要体现在几方面:
1. 有时扩容一个节点,calico-node容器死活起不来,无奈的时候只能把KVstore整个目录干掉,相当于整个集群铲了重建。
2. 一个机器重启,发现起不来了。。然后整个集群重建。
官方overlay的方案相对来说会更可靠,因为它会随着docker每个release的版本不断成熟。相关的例子可以参考nginx商业化后的行为,天然会排斥一些和自己有竞争关系的公司的方案。官方的overlay本质上是走vxlan,性能上可能会calico稍微差一些。
3.1.1 etcd部署
每个方案的实施都是需要先部署一个swarm集群。swarm部署的基础关键在准备好一套KV的方案。因此是简单的测试,所有我做的比较简单
hostname -i
3.1. 2 swarm部署
挑选3个机器部署swarm的管理节点
然后所有的节点起agent join上去
管方的overlay配置比较简单
需要注意指明overlay使用的宿主机器网卡
之前网上都传PHP7得性能相对于PHP5有大幅的提升。简单做了一次升级
rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
yum remove -y php-common && yum install php70w-fpm php70w-opcache php70w-mysql
systemctl restart php-fpm
对比一下升级前后的首页cache不命中时RT变化 0.363s VS 0.097。
可以确定升级后的rt有大幅下降。
乘着双11的时候在阿里云买了一台vm,替换之前申请的AWS的机器。因此大陆访问AWS的机器实在是卡的不能用。。
此次乘着重新迁移,把wordpress部署写成了一个salt的sls文件。
www-data:
user.present:
- shell: /bin/false
- createhome: False
group.present:
- addusers:
- www-data
blog-pkgs:
pkg.installed:
- pkgs:
- nginx
- mariadb-server
- php-fpm
- php-mysql
- php
- tcpdump
{% for d in ["log/mysql","run/mysqld" ]: %}
/var/{{d}}:
file.directory:
- user: mysql
- group: mysql
- recurse:
- user
- group
- makedirs: true
{% endfor %}
{% for d in [ "/var/log/nginx/","/var/cache/nginx","/var/lib/nginx/tmp/fastcgi"]: %}
{{d}}:
file.directory:
- user: www-data
- group: www-data
- makedirs: true
- require:
- user: www-data
{% endfor %}
{% for f in ["dhparam.pem","server.crt.2016","server.key.2016"]: %}
/etc/nginx/cert/{{f}}:
file.managed:
- source: salt://base/conf/nginx/{{f}}
- makedirs: true
{% endfor %}
mariadb:
service.running:
- enable: True
- reload: True
- watch:
- file: mysql-conf
- require:
- file: mysql-conf
php-fpm:
service.running:
- enable: True
- reload: True
- watch:
- file: php-conf
- require:
- file: php-conf
nginx:
service.running:
- enable: True
- reload: True
- watch:
- file: /etc/nginx/conf.d/443.conf
- require:
- user: www-data
nginx_reload:
cmd.wait:
- name: systemctl reload nginx
- watch:
- file: /etc/nginx/conf.d/443.conf
- file: /etc/nginx/nginx.conf
- file: /etc/nginx/fastcgi_params
php_reload:
cmd.wait:
- name: systemctl reload php-fpm
- watch:
- file: php-conf
/etc/nginx/conf.d/443.conf:
file.managed:
- source: salt://base/conf/nginx/443.conf
- template: jinja
/etc/nginx/nginx.conf:
file.managed:
- source: salt://base/conf/nginx/nginx.conf
- template: jinja
/etc/nginx/fastcgi_params:
file.managed:
- source: salt://base/conf/nginx/fastcgi_params
- template: jinja
mysql-conf:
file.managed:
- name: /etc/my.cnf
- source: salt://base/conf/mysql/my.cnf
- template: jinja
php-conf:
file.managed:
- name: /etc/php-fpm.d/www.conf
- source: salt://base/conf/php/www.conf
- template: jinja
[root@CentOS base]# cat init.sls
www-data:
user.present:
- shell: /bin/false
- createhome: False
group.present:
- addusers:
- www-data
blog-pkgs:
pkg.installed:
- pkgs:
- nginx
- mariadb-server
- php-fpm
- php-mysql
- php
- tcpdump
{% for d in ["log/mysql","run/mysqld" ]: %}
/var/{{d}}:
file.directory:
- user: mysql
- group: mysql
- recurse:
- user
- group
- makedirs: true
{% endfor %}
{% for d in [ "/var/log/nginx/","/var/cache/nginx","/var/lib/nginx/tmp/fastcgi"]: %}
{{d}}:
file.directory:
- user: www-data
- group: www-data
- makedirs: true
- require:
- user: www-data
{% endfor %}
{% for f in ["dhparam.pem","server.crt.2016","server.key.2016"]: %}
/etc/nginx/cert/{{f}}:
file.managed:
- source: salt://base/conf/nginx/{{f}}
- makedirs: true
{% endfor %}
mariadb:
service.running:
- enable: True
- reload: True
- watch:
- file: mysql-conf
- require:
- file: mysql-conf
php-fpm:
service.running:
- enable: True
- reload: True
- watch:
- file: php-conf
- require:
- file: php-conf
nginx:
service.running:
- enable: True
- reload: True
- watch:
- file: /etc/nginx/conf.d/443.conf
- require:
- user: www-data
nginx_reload:
cmd.wait:
- name: systemctl reload nginx
- watch:
- file: /etc/nginx/conf.d/443.conf
- file: /etc/nginx/nginx.conf
- file: /etc/nginx/fastcgi_params
php_reload:
cmd.wait:
- name: systemctl reload php-fpm
- watch:
- file: php-conf
- file: /etc/php.ini
/etc/nginx/conf.d/443.conf:
file.managed:
- source: salt://base/conf/nginx/443.conf
- template: jinja
/etc/nginx/nginx.conf:
file.managed:
- source: salt://base/conf/nginx/nginx.conf
- template: jinja
/etc/nginx/fastcgi_params:
file.managed:
- source: salt://base/conf/nginx/fastcgi_params
- template: jinja
mysql-conf:
file.managed:
- name: /etc/my.cnf
- source: salt://base/conf/mysql/my.cnf
- template: jinja
php-conf:
file.managed:
- name: /etc/php-fpm.d/www.conf
- source: salt://base/conf/php/www.conf
- template: jinja
/etc/php.ini:
file.managed:
- source: salt://base/conf/php/php.ini
迁移的过程中遇到几个问题:
1. 迁移有后会造成首页白屏幕。查了很久才发现是nginx配置文件内默认参数的差异导致。centos默认的fastcgi_param内没带SCRIPT_FILENAME。
解决方案,fastcgi_params内新增以下配置
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
$curl -I https://blog.gnuers.org
HTTP/1.1 200 OK
Server: nginx/1.10.1
Date: Tue, 22 Nov 2016 02:19:41 GMT
Content-Type: text/html; charset=UTF-8
Connection: keep-alive
Vary: Accept-Encoding
X-Powered-By: PHP/5.4.16
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Set-Cookie: PHPSESSID=p0r4lcqeqqa8fcog63esrq8686; path=/
Link: <https://blog.gnuers.org/?rest_route=/>; rel="https://api.w.org/"
Cache-status: MISS
Cache-Control: max-age=241
Strict-Transport-Security: max-age=63072000; includeSubdomains; preload
网上搜了一下确认这个是php.ini内的2个问题修改配置后搞定。
session.use_cookies = 0
session.cache_limiter = none
任何一个服务的规模达到一定量级都会出现各种瓶颈点,传统的IDC内部DNS也不例外。根据多年的实际经验把工作中遇到的点集成到了一个图。
主要瓶颈点:
1. DNS记录更新瓶颈
2. DNS同步瓶颈
3. DNS缓存应答瓶颈
4. DNS递归瓶颈
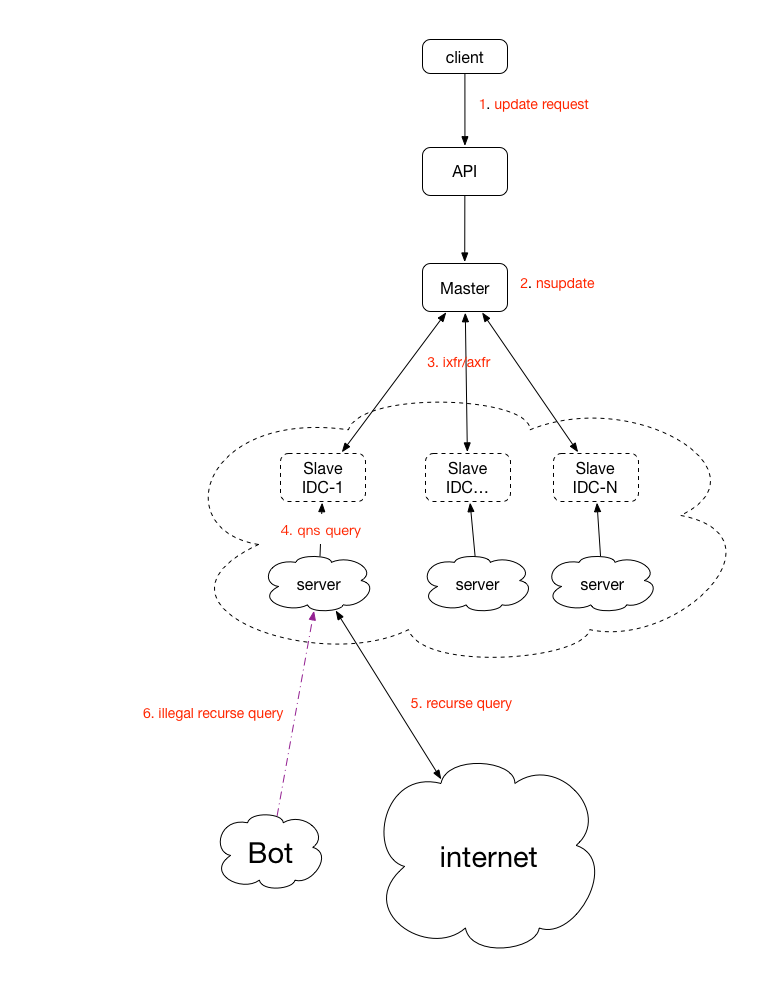
到底多大规模的内网DNS系统能称为大?个人定6个9标准:
1. IDC数量至少9个。
2. 域名全网生效SLA 9s内。
3. 一个IDC的DNS数量大于9台。
4. 调用DNS API的外部业务系统至少9个。
5. 单个机房DNS服务的范围超过9999台服务器。
6. DNS系统内的域名zone数量超过99个。
如果你管理的内网DNS系统规模满足一半以上的条件,想必你也会遇到各种奇葩的问题。从上图给出的几个瓶颈点出发几个优化的建议:
1. 控制外部API的调用并发,如果有的系统需要批量更新大量的域名,可以使用合并发送nsupdate操作的模式,注意单个nsupdate报文不要超过65535字节.
2. dns master服务器最好使用SSD服务器,因为nsupdate操作时zone文件的频繁会写非常消耗IO。
3. master上注意增大serial-query-rate以保证master的notify发送速度,估算值serial-query-rate >=slave规模*同时更新zone数量,实测发送速度可以超过2k/s。
4. master上增大transfers-out的值,需要>=slave规模*同时更新zone数量,
5. slave上transfers-in transfers-per-ns 需要大于本地zone的数量,否则导致新节点启动时因超过quota值部分zone会延迟半个小时以后再同步;slave 上serial-query-rate 超过本地zone的数量。
6. salve机器上常备dnstop分析实时流量。
7. salve服务器上如果有公网IP,务必配置好iptables,放置被当作反射器去攻击他人,并经常会有国安局、公安局领导约谈。